java开发工具的使用
- Intellij IDEA环境使用
- Tomcat使用
xml:平台语言沟通的桥梁
校验:
使用浏览器
xml语法:
XML(eXtensible Markup Language),可扩展标记语言。“可扩展”,即用户可以自定义标记。
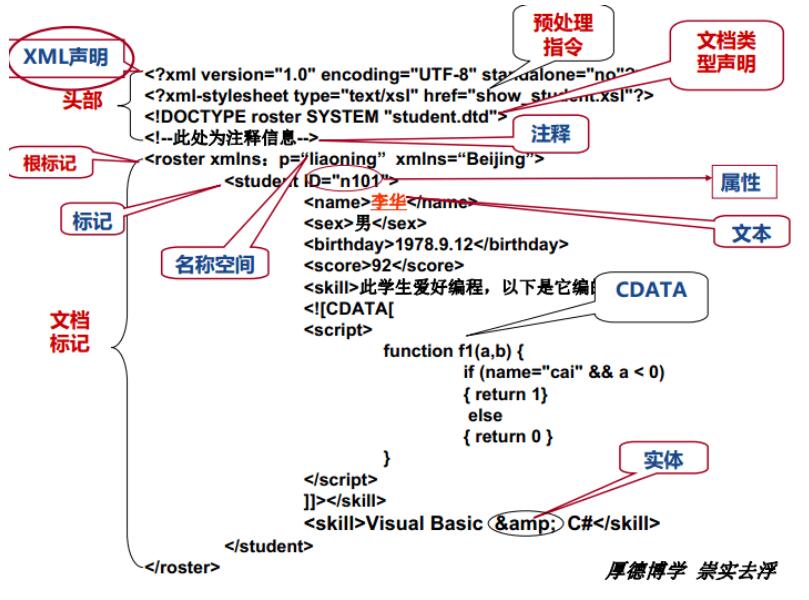
- 文档声明:
<?xml version="1.0" encoding="GB2312" standalone="yes" ?>
XML是一种元语言。<?xml version=“1.0”?>书写xml文件应注意:xml声明语句必须作为文件的第一行; - 根标记:
xml有且仅有一个跟标记,其他标记必须封装在根标记中,文件的标记必须形成树状结构; - 规范的XML:符合W3C制定的规则;
- xml和HTML的主要区别:
① HTML的标记是固定的,预定义的,不可扩展的;而XML的标记是可扩展的,是可以由用户自定义的;
② HTML的标记说明了信息的显示格式;而XML标记表示了数据的逻辑结构及语义; - 字符集(Charset):
一组抽象字符的集合。其中字符(Character)是文字与符号的总称,包括文字、图形符号、数学符号等。英文字符集、繁体汉字字符集、日文汉字字符集;
被编码过的字符集(Coded Character Set) :每种编码都限定了一个明确的字符集合; - ASCII:
美国信息交换标准码; ISO 8859,全称ISO/IEC 8859: ISO8859-1; - Unicode:
UTF-8,Unicode转换格式(Unicode Translation Format,简称UTF);
Unicode的实现方式不同于编码方式。 Unicode的实现方式称为Unicode转换格式(UnicodeTranslationFormat,简称为UTF)。一个字符的Unicode编码是确定的,但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,Unicode编码的实现方式就有所不同。 - UTF-8:大多数常用字符(ASCII中0~127字符)它只使用单字节,而对其它常用字符(特别是朝鲜和汉语会意文字),它使用3字节;
- 汉字编码:
GB2312、BIG5;
GB2312:简体中文字符集,全称为GB2312(80)字符集,共包括国标简体汉字6763个
ANSI:美国国家标准局 <?xml version=“1.0”encoding=“UTF-8”?>以“UTF-8”编码保存 默认;<?xml version=“1.0”encoding=“gb2312”?>以“ANSI”编码保存 ASCII、汉字;<?xml version=“1.0”encoding=“ISO-8859- 1”?>以“ANSI”编码保存ASCII;<!--此处为注释信息-->注释根标记- 标记的命名规则:
必须以字母、下划线(_)或冒号(:)开头;
后面可以跟有效的名字符,有效名字符除了前面的,还包含数字、连接符(-)、句点(.);
英文字母大小写敏感的;
名称不能含有空格;
名称中不能有字符串“xml”,“XML”或以任何顺序排列的这三个字母的组合。W3C保留对三个字母的命名的使用权; - 五种特殊字符:
“ < ”、“ > ”、“ & ”、“ ‘ ”、“ “ ”;
< <;> >;& &;&apos ‘;" “; - 以“
<![CDATA[”作为段开始,以“]]>”作为段结束,段开始和段结束之间称为CDATA段的内容。
CDATA段中的内容可以包含任意的字符。
标记内容可以由两个部分构成:文本数据部分和子标记部分。 一个标记的文本数据包括:普通字符、
CDATA段的内容、字符引用和实体引用。 - 名称空间:有效区分名字相同的标记;
名称空间声明有两种形式:
有前缀名称空间 :xmlns:person=“2203026”;
无前缀名称空:xmlns=“www.tup.com”;
当且仅当它们的名字相同时称两个名称空间相同; URI只是形式上的标识符,唯一的目的是提供一个唯一的名字,并不需要指向一个有效的内容,在URI所标识的位置上,可以不存在任何东西。 - URI(Uniform Resource Identifier),作为名称空间的名字。名称空间的名字不必是有效的,它仅仅是为了区分名称空间的名字而已;
名称空间的引用
(1)有前缀的名称空间:在开始标记和结束标记的名字前面添加名称空间的前缀和冒号来引用名称空间;
(2)无前缀的名称空间:该标记及其子标记都默认地隶属于这个名称空间;
(3)无前缀的名称空间:子标记也可以重新声明名称空间。xml约束:
DTD约束:(内部约束,外部约束)
内部约束:直接写在xml文档中
<?xml version=”1.0” encoding=”gbk”?> <!DOCTYPE 书架(根元素)[ <!ELEMENT 书架 (书+)>//根元素包含的子元素书最少一个 <!ELEMENT 书 (书名,作者,售价)>//子元素必须包含的子标签 <!ELEMENT 书名 (#PCDATA)>//PCDATA表示元素的主体内容为普通文本 <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售价 (#PCDATA)> ]> <书架>
外部约束:外部引入.dtd作为单独的文件存在。文件扩展名.dtd,文件必须用UTF-8编码保存到磁盘上
//dtd文件在本地: <!DOCTYPE 根元素 SYSTEM “dtd文件的地址”> //dtd文件在外地(网上): <!DOCTYPE 根元素 PUBLIC “dtd的名称” “dtd的路径”> //示例: <?xml version="1.0" encoding="gbk"?> <!DOCTYPE TVSCHEDULE SYSTEM "tet.dtd"> <TVSCHEDULE NAME="CCTV"> <CHANNEL CHAN="zh"> <BANNER>文本</BANNER> <DAY> <DATE>文本</DATE> <HOLIDAY>文本</HOLIDAY> </DAY> <DAY> <DATE>文本</DATE> <PROGRAMSLOT> <TIME>文本</TIME> <TITLE>文本</TITLE> <DESCRIPTION>文本</DESCRIPTION> </PROGRAMSLOT> </DAY> </CHANNEL> </TVSCHEDULE>
DTD语法:
DTD的基本结构:① DTD的开始标记定义元素,这是DTD中最主要注释;② 定义元素属性;
XML与DTD的关联:外部DTD关联形式<?xml version="1.0" encoding="gb2312" ?>私有DTD引用<!DOCTYPE 根元素名SYSTEM “DTD文件的URI">;
公共DTD引用:<?xml version="1.0" encoding="gb2312" ?> <!DOCTYPE 根元素名PUBLIC“DTD名称” “DTD文件的URI">
用脚本校验xml是否符合DTD约束
- Schema
Schema语法(会读就可以)
名称空间,著名名称空间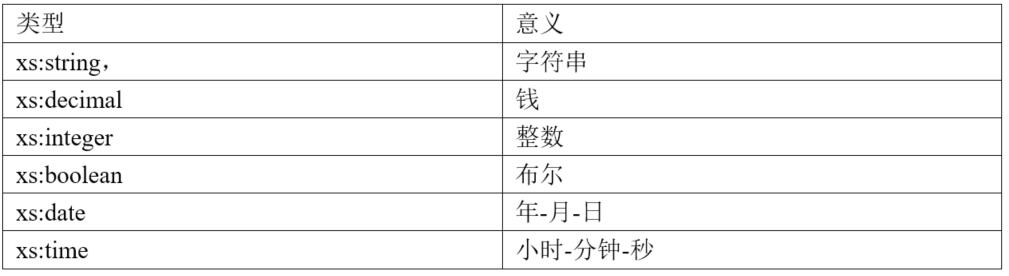
xml解析:
程序对xml的读写,生成相应的对象
dom解析:只需解析一次,生成对象,但加载完整的树之后才开始解析
—dom4j案例
//xml文本 <?xml version="1.0" encoding="UTF-8" standalone="no"?> <State Code="37" Name="山东" description="省会"> <City> <Name>济南</Name> <Region>历下区</Region> </City> <City>青岛</City> <City>威海</City> <City>泰安</City> </State>
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class JaxpDemo {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();//得到创建解析器的工厂:DocumentBuilderFactory
DocumentBuilder builder = factory.newDocumentBuilder();//通过工厂得到解析器:DocumentBuilder
Document document = builder.parse("xml文件路径");//加载xml文件:得到了Document对象
}
public static void test1(Document document){//得到某个具体的节点内容
NodeList nl = document.getElementsByTagName("City");//得到所有的City元素,
Node node = nl.item(2);//索引从0开始
System.out.println(node.getTextContent());//打印获得节点的主体内容
}
public static void test2(Document document){//遍历所有元素节点。
Node rootNode = document.getElementsByTagName("State").item(0);
treewalk(rootNode);
}
public static void treewalk(Node node){//递归
if(node.getNodeType()==Node.ELEMENT_NODE){//是一个元素节点
System.out.println(node.getNodeName());//打印元素的名称
}
NodeList nl = node.getChildNodes();//看看他有没有孩子
for(int i=0;i<nl.getLength();i++){
Node n = nl.item(i);
treewalk(n);//递归
}
}
public static void test3(Document document) throws Exception{//修改某个元素节点的主体内容
Node secondCityNode = document.getElementsByTagName("City").item(1);//找到第2个City元素
secondCityNode.setTextContent("威海");//设置主体内容为:威海
//把内存中的Document写到xml文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult("src/LocList.xml"));
}
public static void test4(Document document) throws Exception{//向指定元素节点中增加子元素节
Element e = document.createElement("City");//<City></City>//创建新元素
e.setTextContent("烟台");//<City>烟台</City>
Node rootNode = document.getElementsByTagName("State").item(0);
rootNode.appendChild(e);//把新元素添加到State最后
//把内存中的Document写到xml文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult("src/LocList.xml"));
}
public static void test5(Document document) throws Exception{//向指定元素节点上增加同级元素节点
Element e = document.createElement("City");//创建新元素
e.setTextContent("青岛");
//调用inertBefore插入新节点:必须由父节点来调用
Node secondNode = document.getElementsByTagName("City").item(1);
secondNode.getParentNode().insertBefore(e, secondNode);
//把内存中的Document写到xml文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult("src/LocList.xml"));
}
public static void test6(Document document) throws Exception{//删除指定元素节点
Node ytNode = document.getElementsByTagName("City").item(4);//得到烟台节点
ytNode.getParentNode().removeChild(ytNode);//用父节点删除
//把内存中的Document写到xml文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult("src/LocList.xml"));
}
public static void test7(Document document) throws Exception{//操作XML文件属性
Node stateNode = document.getElementsByTagName("State").item(0);//看成元素
if(stateNode.getNodeType()==Node.ELEMENT_NODE){
Element e = (Element)stateNode;
System.out.println(e.getAttribute("Name"));
}
}
public static void test8(Document document) throws Exception{//8、添加属性
Node stateNode = document.getElementsByTagName("State").item(0);//看成元素
if(stateNode.getNodeType()==Node.ELEMENT_NODE){
Element e = (Element)stateNode;
e.setAttribute("description", "省会");
}
//把内存中的Document写到xml文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult("src/LocList.xml"));
}
}
